Qwen3 Explained: Main Features and Capabilities


Qwen3 is the third version in the qwen series from Alibaba Cloud. It came out in April 2025. This model has hybrid reasoning modes. You can pick step-by-step thinking for hard tasks. You can also choose quick answers for easy questions. Qwen3 works with 119 languages. This helps people talk to others around the world. The model uses advanced architectures like Mixture-of-Experts. This helps it stay fast and work well. Qwen3 has strong agent abilities. Agents can team up to finish tasks. Qwen3 is open-source. It lets more people use advanced ai for writing, coding, and agent jobs.
Key Takeaways
Qwen3 has two reasoning modes. Thinking Mode helps with hard tasks. Non-thinking Mode gives fast answers. Users can pick speed or accuracy.
Its Mixture-of-Experts design uses only some parts at once. This makes Qwen3 fast and efficient. It can also work with very big models.
Qwen3 works with 119 languages. This helps global projects that need good language skills. It is good for understanding and talking in many languages.
The model has strong agent abilities. Many agents can work together. They can use tools for coding, customer service, and checking data.
Qwen3 can read very long texts with a big context window. This helps with deep talks, long documents, and hard problems.
Qwen3 Features
Hybrid Reasoning Modes
Qwen3 brings hybrid reasoning. This means users can pick between two main ways to use it: Thinking Mode and Non-thinking Mode. This choice lets the model do both hard and easy tasks well.
Thinking Mode is best for things that need steps, like math, code, or making choices. In this mode, qwen3 uses lower temperature and top_p. This gives more careful and correct answers.
Non-thinking Mode is for fast, simple questions. It uses higher temperature and top_p. This makes answers come quicker but with less detail.
Qwen3 lets users set a "thinking budget." This controls how much reasoning the model does. It helps balance quality, speed, and cost for each job.
Here is a table that shows how the two modes are different:
Mode | Purpose | Key Parameters | Functionality Summary |
|---|---|---|---|
Reasoning Mode | Complex, multi-step tasks (math, coding) | temperature=0.3, top_p=0.7 | Detailed chain-of-thought reasoning, higher quality, slower output |
Non-Reasoning Mode | Simple, fast queries | temperature=0.7, top_p=0.95 | Quick, lighter responses, optimized for efficiency |
Developers can use a short code to turn on Thinking Mode:
thinking_params = {
"temperature": 0.3,
"top_k": 50,
"top_p": 0.7,
"max_new_tokens": 1024
}
prompt_with_thinking = f"""<|im_start|>system
You are a helpful assistant.
<|im_end|>
<|im_start|>user
{user_input}
<|im_end|>
<|im_start|>assistant<|thinking|>"""
input_ids = tokenizer.encode(prompt_with_thinking, return_tensors="pt").to(model.device)
outputs = model.generate(input_ids=input_ids, **thinking_params)
response = tokenizer.decode(outputs[0], skip_special_tokens=False)
print(response)
Qwen3's hybrid reasoning makes it a strong open-source llm. It can do deep thinking and give fast answers. This two-mode system helps users get the best results for different questions.
Mixture-of-Experts Architecture
Qwen3 uses a Mixture-of-Experts (MoE) architecture. This makes it different from many other open-source models. The model has many special networks called experts. For each token, qwen3 picks the top two experts using a learned gate. Only about 5-10% of the total parameters work at once. This makes the model faster and saves power.
Dense models use all their parameters for every token. This costs more to run. MoE lets qwen3 grow to 235 billion parameters but still work fast and cheap. The open-source models include both dense and MoE types. They range from 0.6 billion to 235 billion parameters.
Model Variant | Total Parameters | Active Parameters | Request Throughput (req/s) | Input Token Throughput (tok/s) | Output Token Throughput (tok/s) | Median Time to First Token (ms) | Median Inter-Token Latency (ms) |
|---|---|---|---|---|---|---|---|
235B | 22B | 1.60 | 781.20 | 866.14 | 133.39 | 27.53 | |
Qwen3-32B (Dense) | 32B | 32B | 1.35 | 659.47 | 731.17 | 159.27 | 29.37 |
MoE models like Qwen3-235B-A22B only use some of their parameters. This gives high performance with less wait time and lower cost. Smaller MoE models can be as good as or better than bigger dense models in speed and accuracy.
This design supports hybrid reasoning and makes qwen3 a strong open-source choice for tough ai jobs.
Multilingual Support
Qwen3 is great at using many languages. The model works with 119 languages and dialects. This makes it one of the most open-source llm choices for people around the world. Qwen3 was trained on over 36 trillion tokens. These come from books, Q&A, code, and made-up data. This helps it read and write in many languages.
Feature | Evidence |
|---|---|
Number of supported languages | Qwen3 supports 119 languages and dialects. |
Training data scale and diversity | Trained on over 36 trillion tokens, including textbooks, Q&A, code, and synthetic data. |
Advanced architecture | Hybrid reasoning, dynamic mode switching, strong benchmark performance. |
Benchmark performance | Outperforms OpenAI’s o1 and DeepSeek’s R1 in some benchmarks. |
Qwen3 has been tested on many language tests like Multi-IF, INCLUDE, MMMLU, and MT-AIME2024. The model does very well in code, math, and following instructions in many languages. This makes qwen3 a top pick for ai projects that need strong language skills.
Qwen3 uses the EvalScope tool to test how it does on English, Chinese, code, and math.
The model works well in both thinking and non-thinking modes. This shows it is flexible and strong in language tasks.
Agentic Capabilities
Qwen3 is built with strong agent skills. The model is tuned for agentic jobs. This means it can follow hard, multi-step instructions and use outside tools. Qwen3 lets many agents work together on jobs like customer service, data checks, and making reports.
Qwen3 uses a training plan with pretraining, reinforcement learning, and fine-tuning for tool use.
The model remembers what happened in talks, which helps with jobs that need memory and teamwork.
Qwen3 uses a special function-calling format. This makes it easy to link with APIs, browsers, and dev tools.
The model can make structured outputs for tool use. This helps agents finish jobs well.
Qwen3 lets many agents work together using the Multi-agent Collaboration Protocol (MCP). This lets agents pass jobs, chain tools, and watch workflows. For example, in customer service, different agents handle pre-sales and post-sales. This makes things faster and clearer.
Qwen3 agents can be watched and tracked with tools like MLflow. This makes it easier to run big ai systems.
Long Context Window
Qwen3 can use a context window of 32,768 tokens. With YaRN RoPE scaling, this goes up to 131,072 tokens. This big window lets the model handle long documents, code, or talks without missing details.
Model | Maximum Context Window Size (tokens) | Notes on Extension or Special Features |
|---|---|---|
Qwen3 | 32,768 (native) | Up to 131,072 tokens with YaRN RoPE scaling |
Gemini 2.5 | 1,000,000 | Proprietary, extremely large context window |
Gemma 3 | 128,000 | Open-source, multiple parameter sizes |
Cohere Command R+ | 128,000 | Enterprise-focused, large context window |
Cohere Command A | 256,000 | Open-source, research model, supports 23 languages |
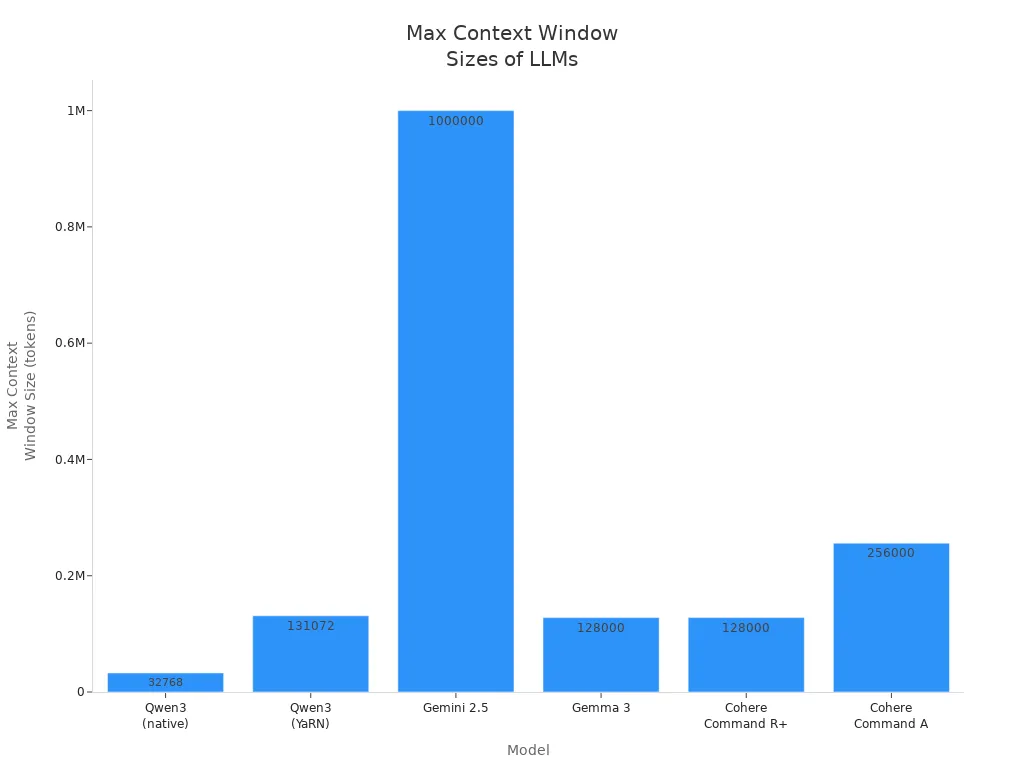
Qwen3's long context window helps with deep talks, document checks, and hard problem solving.
The model can read whole books or code in one go. This is good for research, law, and software work.
Qwen3 is open-source. Its hybrid reasoning, agent skills, and language support make it a top pick for developers and groups who want a flexible and strong ai tool.
Qwen Capabilities
Reasoning and Problem Solving
Qwen3 is very good at solving problems and thinking things through. It uses hybrid thinking modes. This means you can pick step-by-step thinking for hard problems. You can also get quick answers for easy ones. This helps keep answers good while saving computer power. Qwen3 learns in four steps after training. First, it gets better at math, coding, and STEM by practicing long chains of thought. Next, it uses reinforcement learning to try new things and fix mistakes. The model mixes both thinking and non-thinking ways to follow instructions better. It learns from many tasks so it does not make bad choices.
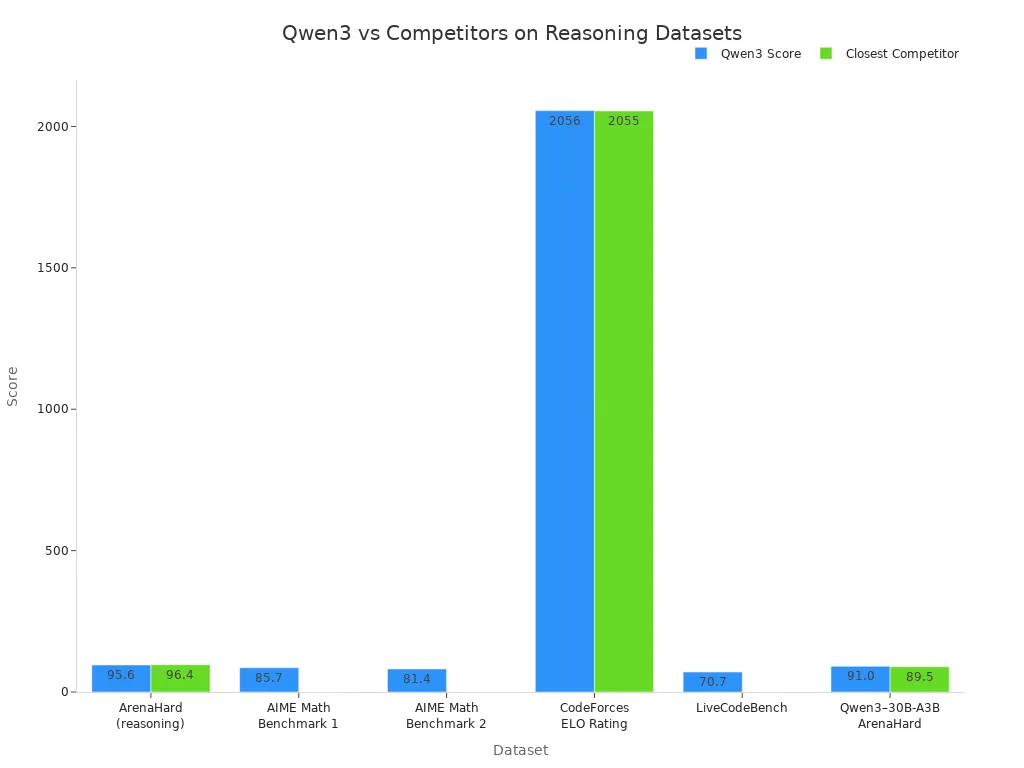
Qwen3 does well on tests. It gets a 95.6 score on ArenaHard for reasoning. This is just below Gemini 2.5 Pro. On AIME Math, Qwen3 beats DeepSeek-R1, Grok 3, and GPT. It also has the highest CodeForces ELO rating of all the models listed.
Dataset / Metric | Qwen3–235B-A22B Score | Closest Competitor Score | Notes |
|---|---|---|---|
ArenaHard (reasoning) | 95.6 | Gemini 2.5 Pro: 96.4 | Qwen3 is just behind Gemini 2.5 Pro |
AIME Math Benchmark 1 | 85.7 | DeepSeek-R1, Grok 3, GPT | Outperforms these competitors |
AIME Math Benchmark 2 | 81.4 | DeepSeek-R1, Grok 3, GPT | Outperforms these competitors |
CodeForces ELO Rating | 2056 | Others < 2056 | Highest among listed models |
LiveCodeBench | 70.7 | Gemini (higher) | Qwen3 ranks second |
Coding and Math
Qwen3 is great at coding and math. It is trained to follow instructions for math, code, and facts. Qwen3-14B and Qwen3-32B learn from big sets of math and code data. The model can do step-by-step thinking, logic, and hard math. Qwen3 can write, read, and fix code in Python, JavaScript, and C++. The Qwen3-Coder-480B-A35B-Instruct model is made for agent coding jobs. It can call functions and work with big code projects. This agent can make hard code and connect with APIs and dev tools.
Multilingual Tasks
Qwen3 works well with many languages. It supports 119 languages and dialects from big language groups. Qwen3 stays accurate when reasoning in different languages. It does not lose much performance in native languages, unlike smaller models. Using English for reasoning helps, but Qwen3 shows less difference than others. The model does well on tests like MMLU and MGSM. It beats DeepSeek-V3 and Qwen2.5 in accuracy. Qwen3 trains on 36 trillion tokens. This helps it read and write in many languages. It is a good choice for global ai projects.
Aspect | Details |
|---|---|
Languages Supported | 119 languages and dialects across major language families |
Multilingual Tasks | Multilingual understanding benchmarks such as MGSM and MMMLU |
Comparative Accuracy | Outperforms DeepSeek-V3 and Qwen2.5 in multilingual understanding tasks |
Model Efficiency | MoE models match or exceed larger dense models with fewer active parameters |
Tool Integration
Qwen3 makes it easy to use tools with agents. It works with Hugging Face, ModelScope, and Kaggle using APIs. You can also run it on your own computer with Ollama, LMStudio, and llama.cpp. Qwen-Agent helps by wrapping tool templates and parsers. Agents can set up tools with files or custom setups. Qwen3 can call functions by changing prompts. This lets it pick when and how to use outside functions. The model uses Hermes-style tags for tool calls in many steps. This helps with things like answering table questions and reading code. These features help agents finish hard jobs and work together well.
Qwen3 vs Others
Previous Qwen Models
Qwen3 is better than older Qwen models. The new ones, like Qwen3-30B-A3B and Qwen3-4B, work faster and cost less. People see that it gives quicker answers and smoother results. Qwen3 does not just get bigger. It tries to be smart and save power, even in small models. You can set how much thinking Qwen3 does for each job. This helps you use less power and get better answers.
The biggest Qwen3 models use a mixture-of-experts setup. Only a small part of the model works at one time. This makes it run faster and cheaper. The dense Qwen3 models use old ways but learn from more data and new training tricks. Small Qwen3 models can beat bigger old models in tests.
Model | Architecture | Context Length | Best For |
|---|---|---|---|
Qwen3-235B-A22B | MoE | 128K | Research tasks, agent workflows, long reasoning chains |
Qwen3-30B-A3B | MoE | 128K | Balanced reasoning at lower inference cost |
Qwen3-32B | Dense | 128K | High-end general-purpose deployments |
Qwen3-14B | Dense | 128K | Mid-range apps needing strong reasoning |
Qwen3-8B | Dense | 128K | Lightweight reasoning tasks |
Qwen3-4B | Dense | 32K | Smaller applications, faster inference |
Qwen3-1.7B | Dense | 32K | Mobile and embedded use cases |
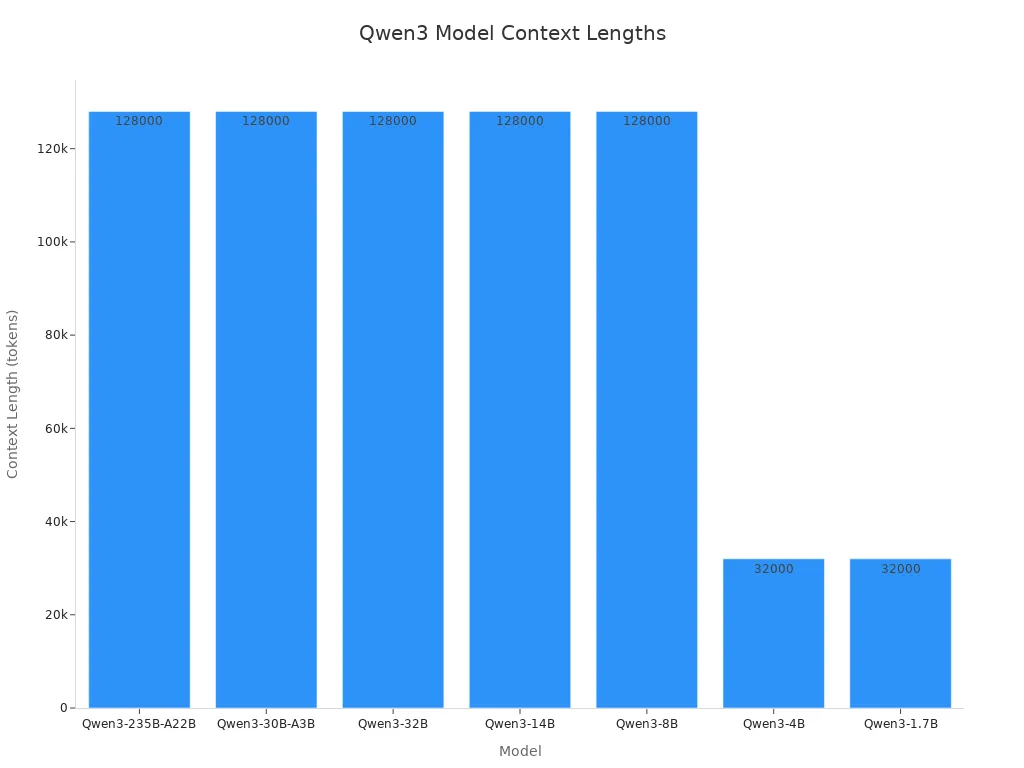
Most Qwen3 models can handle up to 128,000 tokens. This helps with long papers and hard agent jobs. Qwen3 is open-source and has free trials. This makes it easy for developers to try in real ai projects.
Competing LLMs
Qwen3 is different from other big language models. It uses a mixture-of-experts design. Only a few experts work for each token. This makes it fast and strong. Qwen3 can use up to 128,000 tokens at once. This is much more than LLaMA 3, which only uses 8,000 tokens. Qwen3 learns from 36 trillion tokens in 119 languages. This helps it understand many languages and think well.
Qwen3 is as good as or better than GPT-4 and Gemini 2.5 Pro in many tests. It is very good at coding, math, and agent jobs. Qwen3 is open-source, so people can run it on their own computers. This makes it easier to use than closed models.
Aspect | Qwen3 | Gemma 3 |
|---|---|---|
Reasoning | Great at hard math, code, and agent jobs; best at coding and agent work | Good at STEM and reasoning; close to Qwen3 but a bit behind |
Language Support | Works with over 100 languages and follows instructions well | Works with over 140 languages and is better at non-English |
Architecture | Dense and MoE Transformer; up to 235B parameters; can change reasoning depth | Decoder-only Transformer; up to 27B parameters; saves memory |
Efficiency | MoE models are fast and save resources; open for everyone | Fast on one GPU; works well with Google Cloud |
Agent & Function Calling | Advanced agent skills and function calling | Has built-in function calling and structured outputs |
Qwen3’s strong results, big context window, and agent skills make it a great pick for people and groups who want smart, fast ai.
Qwen3 Access
Deployment Options
Developers and groups have different ways to use qwen models. The main choices are:
If you use a Virtual Private Cloud (VPC), you control your data and setup. This is good for teams that want strong security and privacy.
With a managed SaaS from Predibase, you do not need to buy GPUs. Predibase gives you ready H100 clusters, quick setup, and grows as you need. This helps teams start fast and handle busy times easily.
Hyperstack cloud is another choice. You make an account, set up payment, and pick NVIDIA A100 GPUs for your model. The platform shows you each step, so it is easy to follow.
What you need depends on the model size:
Model Size | Hardware Needed | Best Use Case |
|---|---|---|
Small (e.g., 8B) | Single H100 or L40s GPU | Local or small team projects |
Medium (14B, 32B) | One H100 GPU | Business or research tasks |
Large (235B-A3B) | Four H100 GPUs | Enterprise or advanced research |
Both VPC and SaaS keep your data safe. VPC gives you the most control. SaaS gives you fast setup and easy scaling. MoE models save money by using only some parameters each time. This helps teams choose between speed, cost, and how well it works.
Tip: SaaS can be ready in minutes and meets top security rules like SOC 2 Type 2.
Getting Started
Anyone can use qwen open-source models by doing these steps:
Get your computer ready. Make sure it has a new CPU or GPU, enough RAM, and storage. Install Python 3.8 or newer, Git, and Docker if you need them.
Download the models from trusted places like Hugging Face or ModelScope.
Use Ollama to run the model on your computer. Install Ollama, check your setup, and start the model with simple commands.
Try LM Studio for a visual way. Download LM Studio, add the model, set the options, and start the server.
If you know more, install vLLM with pip. Run the model and change settings like reasoning mode and token limits.
Test the API with tools like Apidog. This checks if the model works and helps you connect it to other things.
You can find guides and tutorials on Hugging Face, ModelScope, and the qwen docs site. These guides show how to turn thinking mode on or off, set up how the model works, and use it with vLLM and SGLang. There are also step-by-step guides for cloud sites like DigitalOcean and Hyperstack.
New users may have trouble with computer needs, setup mistakes, or turning on special features like thinking mode. Visual tools and automation sites like Latenode make things easier. Learning step by step and using official guides helps teams avoid mistakes and get the best from their ai models.
Qwen models are special because they use hybrid reasoning modes. They also work with 119 languages and have strong agentic features. You can pick step-by-step thinking or quick answers. This makes qwen models good for many jobs. The system can read long documents. It also works with tools for coding, math, and workflow tasks.
People using Qwen say code reviews are faster now. Biotech labs see better automation. Students learn more in school. Qwen helps teams save time and make fewer mistakes. It also helps them get more work done.
Anyone can try Qwen by downloading it from trusted sites. You can also use cloud APIs to set it up easily.
FAQ
What makes qwen different from other AI models?
Qwen uses hybrid reasoning and agentic features. It supports many languages. The model can handle long documents. Qwen also offers open-source access. These features help users solve many types of tasks.
Can qwen3 work with other tools or software?
Qwen3 connects with tools like Hugging Face, ModelScope, and Kaggle. Users can run it on their own computers. Qwen also works with APIs and coding platforms. This helps teams use it in many projects.
How does qwen help with language tasks?
Qwen supports 119 languages and dialects. It can translate, summarize, and answer questions in many languages. The model keeps high accuracy in both English and non-English tasks.
Is qwen easy to set up for new users?
New users can download qwen from trusted sites. They can use visual tools like LM Studio or Ollama. Guides and tutorials help with setup. Qwen works on many computers and cloud platforms.
Who should use qwen3?
Developers, students, and businesses can use qwen3. It helps with coding, writing, and research. Qwen supports teamwork and automation. The model fits many needs, from school projects to company workflows.
See Also
A Candid Comparison Between Momen And Bubble Features
Best Five AI App Builders To Substitute Vercel v0
Selecting Between Softr And Momen For Business Growth
