A Beginner’s Guide to Multimodal in 2025


Multimodal in 2025 means AI can understand text, images, audio, and video all at once. These systems mix different types of information to give smarter answers. Multimodal AI is now used in many daily tools. Personal assistants can understand both what you say and the photos you show. AI copilots help with emails, schedules, and notes. They do this by knowing more about what is happening.
Users get faster help, better accuracy, and more natural conversations because of multimodal integration.
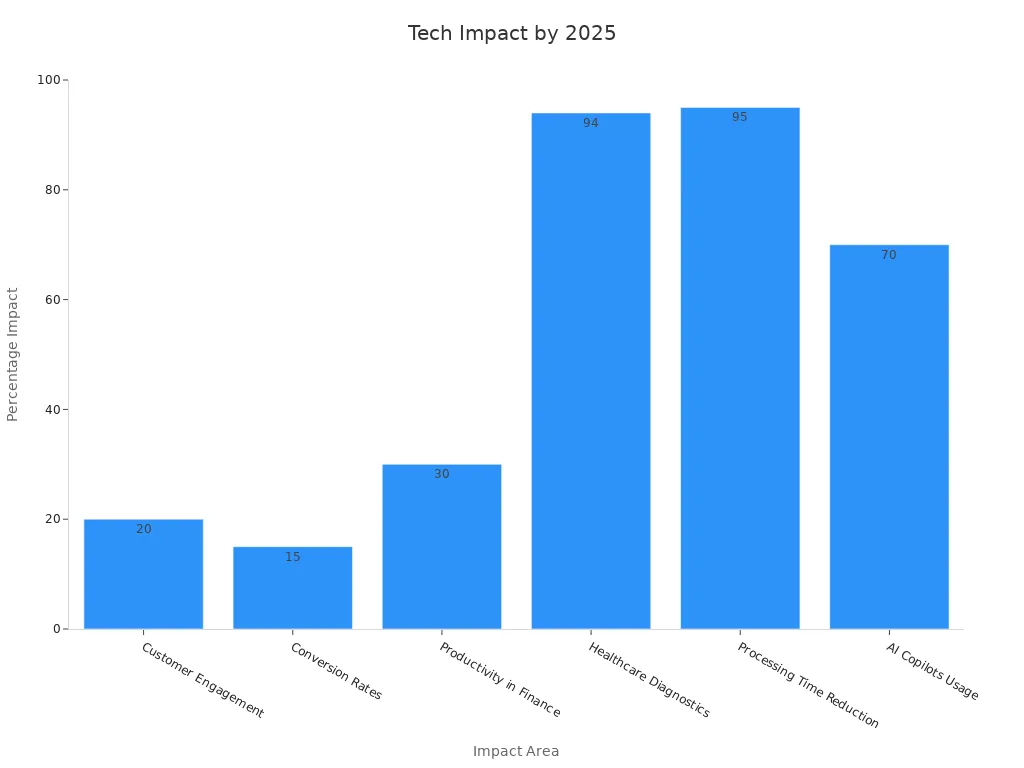
Impact Area | Measurable Impact / Metric | Example / Explanation |
|---|---|---|
Customer Engagement | Multimodal AI understands different data, so people interact more. | |
Conversion Rates | 15% boost | Multimodal AI gives personal experiences, so results are better. |
Productivity in Finance | 30% improvement | AI looks at many documents at once, so work gets done faster. |
Healthcare Diagnostics | 94% accuracy | Using images, records, and audio together helps doctors find problems. |
Processing Time Reduction | 95% reduction (e.g., loan agreements in 6 min) | AI agents do tasks much faster than people can. |
AI Copilots Usage | Nearly 70% of Fortune 500 employees | AI copilots do simple jobs, so workers can do more important things. |
Personal AI Assistants | Enhanced multimodal capabilities | Assistants handle daily jobs better because they understand more. |
Key Takeaways
Multimodal AI uses text, images, audio, and video together. It can understand and answer better than old systems. This technology helps people get answers faster and more correctly. It also makes answers sound more natural in tools like personal assistants and AI copilots. Multimodal AI helps many areas, especially healthcare, by mixing different data types. This helps find problems more easily. Using many kinds of data at once makes AI smarter. It also makes AI more helpful for real-life tasks like shopping, scheduling, and customer support. No-code platforms like Momen let anyone build multimodal AI apps. This makes advanced technology easy and open for everyone.
Multimodal Meaning
Simple Definition
Multimodal means technology can use information from many sources. It can work with text, images, audio, and video. In 2025, multimodal AI uses strong neural networks to handle all these at once. This lets machines see, hear, and read like people do. For example, a multimodal model can look at a picture, listen to a voice message, and read a caption. Then it gives one smart answer. These systems use deep learning models that mix skills from computer vision, speech recognition, and natural language processing. Multimodal learning helps AI agents link what they see, hear, and read. This makes their answers more correct and helpful.
Why It Matters
Multimodal AI changes how people use technology. Now, users want devices to understand words, pictures, sounds, and videos. This makes talking to devices feel more normal and gives better results. Multimodal models do better than old single-mode systems in many ways. In healthcare, using medical images, doctor notes, and patient audio together helps doctors find problems more easily. Recent studies show that multimodal AI helps predict diseases and improves healthcare by using lots of data. Big datasets, like the MIMIC database, help these systems learn and get better.
A report from MIT Technology Review shows that multimodal AI is growing fast in many fields. Companies use these systems in healthcare, cars, media, and telecom to make smarter choices. Upgrades to popular AI tools, like ChatGPT, show that more tools are becoming multimodal. These changes show that AI needs to handle real-world tasks that use more than just text. By using computer vision, text analysis, and speech recognition together, multimodal AI gives better and more useful experiences for everyone.
Multimodal AI is not just a new thing. It is very important for the future, making technology smarter and more useful in daily life.
Key benefits of multimodal AI:
Better understanding of user needs
More accurate and reliable answers
Faster and more natural interactions
How Multimodal AI Works

Input to Output
Multimodal AI systems have a simple process. First, users give different kinds of data. They might upload a photo, ask a question out loud, or type a message. These systems can use text, images, audio, and video at once. Neural networks help the AI understand each kind of input.
Next, the system uses data fusion. This means the AI mixes information from all the sources. For example, it connects what it sees in a picture with what it hears in a voice note. Neural networks, computer vision, and natural language processing work together. This helps the AI find patterns and details that single-mode systems miss.
The last step is output. The AI gives an answer using all the information it got. The answer could be a text message, a spoken reply, or a new image. Multimodal conversational AI makes these talks feel smooth and real. Users get answers that use every part of their input.
A big healthcare study tested over 14,000 multimodal models. The results showed that using more types of data made accuracy better by up to 27.7%. These results show that mixing text, images, and other data helps AI make better guesses. In business, multimodal AI does jobs like writing meeting notes and helping customers. This cuts down on manual work and makes things faster from start to finish.
Multimodal AI systems use data fusion and neural networks to give smarter, faster, and more correct answers.
Real-World Example
A common example is searching for something using both voice and image. Imagine someone wants to find a certain pair of shoes. They take a photo of the shoes and say, "Show me shoes like this in size 9." The multimodal AI gets both the photo and the spoken request. It uses computer vision to look at the photo and natural language processing to understand the words.
The AI mixes these inputs. It matches the shoe style from the photo with the size from the voice. The system then looks at online stores and shows shoes that match both the look and the size. This kind of search feels easy and normal for users. Multimodal conversational AI lets people ask questions in different ways and get better answers.
Other examples are virtual assistants that can read a calendar, listen to a meeting, and look at shared files at the same time. These assistants use multimodal models to help with reminders, scheduling, and even making meeting summaries. Being able to use many kinds of data makes multimodal AI better than older systems.
Multimodal AI changes how people use technology by making every talk smarter and more useful.
Multimodal AI vs Others
Unimodal vs Multimodal
Unimodal AI works with only one kind of data. For example, it might just read text or only look at pictures. Multimodal AI uses many types of data at the same time. It can read, see, and listen together. This helps it understand things better. Imagine unimodal AI as a person who can only hear but cannot see. Multimodal AI is like someone who can use all their senses at once.
Researchers have tested both types in real-life jobs. The results show that multimodal ai often does better. For example:
A prostate cancer model used images and clinical data and got an AUC of 0.837. The unimodal model, with only images, got 0.779.
A COVID-19 model mixed X-ray images and lab data and reached an AUC of 0.854. The unimodal model scored 0.770.
For diabetes risk, a review found unimodal models had an average AUC of 0.81. Multimodal models reached 0.88.
Study/Review | AI Model Type | Average AUC | Notes |
|---|---|---|---|
Diabetes Risk Prediction | Unimodal | 0.81 | Performance varied |
Diabetes Risk Prediction | Multimodal | 0.88 | Superior performance |
A review of 97 studies found that 91% showed multimodal ai did better than unimodal ai. The middle improvement in performance was 0.04 AUC. These results show that using different data types helps make better decisions.
Generative AI
Generative AI makes new things like text, pictures, or music, usually from one kind of input. Multimodal AI is different because it can understand and make things using many types of data at once. This makes it more useful and flexible in real life.
New models show how multimodal ai has special strengths. For example, the Flamingo model did best on six out of sixteen tasks with only a few examples. IMAGEBIND used zero-shot learning with six kinds of data, like images, text, and audio. UNIFIED-IO 2 did well on over thirty-five datasets, working with text, images, audio, video, and actions together.
Model | Highlights | Unique Advantages Over Generative AI | Use Cases and Modalities Covered |
|---|---|---|---|
Flamingo | Best on 6/16 tasks with few examples | Few-shot learning with little data | Visual QA, captioning, multiple-choice visual QA |
IMAGEBIND | Zero-shot recognition with six types of data | Extends zero-shot to images, text, audio, depth, thermal, IMU | Cross-modal retrieval, detection, generation |
UNIFIED-IO 2 | Top results on GRIT benchmark, great on 35+ datasets | Uses text, image, audio, video, and action in one system | Vision-language, image generation, video/audio tasks |
These models show that multimodal ai is more adaptable and smart with context. It can do hard jobs that need many kinds of information. This makes it great for jobs where knowing the whole story is important.
Multimodal AI brings together many senses. This gives machines a richer view of the world and helps them make smarter choices.
Multimodal AI Uses

Everyday Life
People use technology in easier ways now because of multimodal AI. Many people talk to voice assistants at home and on their phones. About 74% of people use voice assistants at home, and 71% like speaking instead of typing. These assistants can understand both what you say and what you show. This makes daily jobs simpler. For example, you can show a picture of something and ask for its price or details. You can search using both photos and your voice. This makes things feel smoother.
Text, pictures, sound, and video are all important in these tools. Almost every multimodal system uses text. About 95% use pictures, and 75% use sound. Video and other senses are being used more now. AI assistants can read messages, know faces, and answer spoken questions. These new tools help people plan their day, shop online, and control smart home gadgets. The multimodal AI market is growing fast. This shows how useful these tools are in daily life.
Industries
Many industries use multimodal AI to fix hard problems and make things better. Healthcare is growing the fastest, with a rate of 42.75%. This is because doctors use AI to look at MRI, CT, and X-ray images together. This helps them find health problems more easily. In eCommerce, companies use AI helpers that speak many languages and give personal help. These tools help shoppers find what they want and get answers in their own language.
Schools also use multimodal AI. Learning websites use text, pictures, and video to make lessons more fun. In finance, companies like GoTo in Indonesia use AI helpers for sending money and paying bills by voice. The table below shows how different industries use multimodal AI:
Industry | Key Statistic / Adoption Driver | Examples of Multimodal AI Use Cases |
|---|---|---|
Healthcare | 42.75% CAGR, imaging fusion | Symptom tracking, telemedicine |
eCommerce | High adoption, smartphones | Virtual assistants, support |
Education | Digital transformation | Interactive learning |
These tools work because of better deep learning and large language models. Multimodal AI now helps with smarter searches, better suggestions, and faster answers in many jobs.
Building AI Apps with Multimodal AI using Momen (Without Code!)
Momen's AI Agent Builder: Your Gateway to Multimodal AI
Momen gives people a strong tool to make AI apps without coding. The AI Agent Builder lets you use text, images, audio, and video together. This tool creates a new way for people to use apps. You can drag and drop different types of data and set up steps that match real needs. The platform helps the AI understand more, so it can make better choices using all the information.
With Momen, teams can make apps that feel richer and more helpful. The new way of using apps makes every action feel easy and useful. For example, a healthcare app can use patient notes, medical pictures, and voice messages at the same time. This helps get better results and makes the app easier to use. Momen’s way lets people see how AI can help anyone build smart tools for daily life.
Tip: Momen’s no-code builder lets everyone try a new way to use apps, making advanced AI easy for all.
Challenges
Building with multimodal AI has some hard parts. Mixing text, images, and audio can be tricky. Teams need to make sure the AI understands each kind of data and links them the right way. Sometimes, the system needs more training to work its best. The new way of using apps also needs good design. Developers have to think about how people use the app and keep it simple.
In the future, AI apps will connect even more and get smarter. More platforms will add multimodal features. The new way of using apps will change how people use technology, making things more personal and quick. Momen is leading this change, helping people build the next wave of AI apps.
Multimodal technology helps machines use text, pictures, sound, and video at the same time. Studies show that using many types of data helps models predict health better than old systems. New methods can guess missing information and still give good results. You can find multimodal features on your phone or smart device. Try using a photo and your voice to search for something.
See how these tools make jobs simpler and answers better.
FAQ
What is the main benefit of multimodal AI?
Multimodal AI uses text, images, audio, and video together. This helps the system understand things better. People get answers that are more correct and useful for daily life.
How does multimodal AI improve healthcare?
Doctors look at medical images, notes, and voice recordings all at once. This helps them find health problems faster and with more accuracy. Patients get better care in hospitals.
Can someone build a multimodal AI app without coding?
Yes, you can. Tools like Momen let people build apps without code. You can drag and drop different kinds of data. This makes it easy for anyone to make smart apps.
What devices use multimodal AI today?
Many phones, smart speakers, and assistants use multimodal AI now. These devices can understand voice, pictures, and text. People find it easier to talk and get help from them.
Is multimodal AI safe to use?
Multimodal AI follows strong privacy and safety rules. Developers keep user data safe with encryption and updates. People should always check their device privacy settings.
See Also
Complete 2025 Handbook For Developing Your MVP Successfully
Learn Ways To Profit From AI Technology In 2025
Step-By-Step Guide To Building AI Trip Planner Using Momen
Create An AI Meeting Assistant With Momen To Simplify Meetings
Top 15 SEO Blogging Tips For Writing Effective Posts In 2025
