Which Large Language Model is Best for Your App in 2025
Choosing the right language model for your app in 2025 depends on what you need. Factors like speed, price, and special features are important. The best large language model options, such as OpenAI GPT, Claude, Gemini, QwQ, and DeepSeek, excel in different areas. For instance, some are great at chatting, while others are better at solving problems or coding. Understanding how these models align with your goals will help you make the best choice.
Key Metrics for Picking the Best Large Language Model
Intelligence and Accuracy
When picking a language model, smartness and accuracy matter most. These show how well a model understands and helps your app. Tests like TruthfulQA check if models give honest answers. MATH tests how well they solve math problems. For general knowledge, MMLU-Pro checks accuracy better. GPQA uses tough expert questions to test models.
Here’s a table of key tests and what they check:
Benchmark | What It Tests |
|---|---|
TruthfulQA | Checks if the model gives honest answers and avoids mistakes. |
MMLU-Pro | Improves reasoning by giving ten choices per question. |
GPQA | Uses hard expert questions to test facts and difficulty. |
MATH | Includes tough high school math problems. |
IFEval | Tests if models follow clear instructions with strict rules. |
These tests help you pick a model that works well and handles hard tasks easily.
Speed and Latency
Speed is super important for apps. A fast model gives quick answers, which is great for live apps. Different models have different speeds. For example, Gemini 2.0 Flash answers in 4.2 seconds. DeepSeek-R1 takes 81 seconds.
The chart below shows how fast models respond:
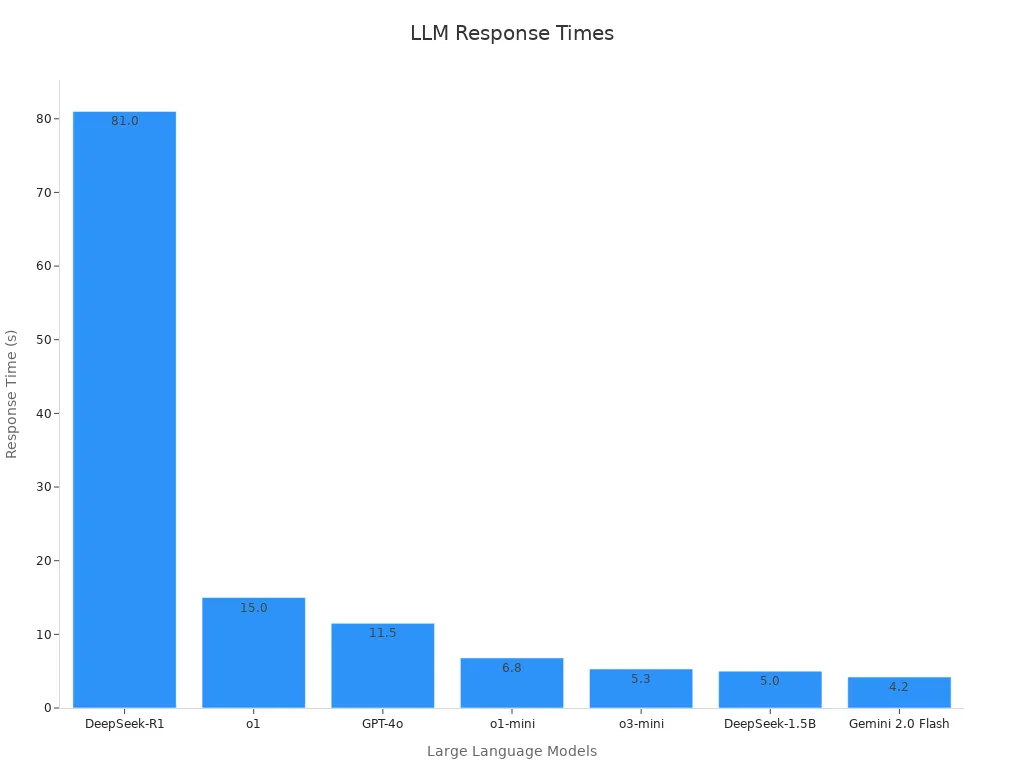
Picking a fast model keeps your app running smoothly, even when busy.
Cost Efficiency
Cost is another big factor. You need good performance without spending too much. Tests like coding and reasoning help check a model’s skills. Coding is tested with 100 math problems. Reasoning is checked with tricky questions without hints. These tests make sure you get good value for your money.
Benchmark Type | What It Tests |
|---|---|
Coding Ability | |
Reliability | Compares answers to real facts from news stories. |
Reasoning | Tests tricky math questions without hints to check thinking skills. |
By looking at these tests, you can find a model that’s smart, fast, and affordable for your needs.
Context Window and Memory
The context window shows how much data a model can handle. Bigger context windows help with long tasks like reading documents or chats. MemLong architecture boosts memory by saving and using past data in parts. This helps the model find useful details from stored memory. It’s great for apps needing deep analysis or ongoing conversations.
Using examples during tasks makes models more accurate. Models like FlanT5 and GPT-3 work better with examples. But in zero-shot tasks, no examples are given. Some models do well without examples, while others need at least one.
FlanT5 and GPT-3 versions d-002 and d-003 improve with examples.
Weak prompts benefit most from 1 to 3 examples.
Accuracy changes based on the number of examples, as seen in Table 2.
For apps handling long chats or documents, pick models with strong memory and flexible context windows.
Scalability and Customization
Scalability means your app can grow without slowing down. Some models handle more users better than others. OpenAI GPT and Gemini are great for busy apps. QwQ works well for smaller apps with fewer users.
Customization lets you change a model to fit your app. Fine-tuning adjusts the model to focus on tasks like coding or support. Bring Your Own Model (BYOM) tools make this easier. Platforms like Momen let you add models like DeepSeek or Claude to your system.
Fine-tuning makes models better at specific tasks.
BYOM helps add custom models from cloud services.
Scalable models like OpenAI GPT handle more users easily.
By focusing on scalability and customization, your app can grow and stay useful for users.
Comparison of Large Language Models

OpenAI GPT: Flexible and Smart
OpenAI GPT is known for being flexible and very smart. Its newest version, GPT-4o, is better at solving problems and thinking logically. It’s great for tasks needing creative ideas or advanced reasoning. It works with all ChatGPT tools like APIs, function calling, and image inputs, making it useful for many apps.
This model can handle text, voice, and images together. For example, it can look at a picture, explain it, and share related facts. Its improved audio feature makes it sound more emotional and natural. Even with these upgrades, GPT-4o stays fast and gives quick answers without losing accuracy.
Feature | |
|---|---|
Better Reasoning Skills | Improved at solving problems and logical thinking. |
Tool Support | Works with all ChatGPT tools like APIs and image inputs. |
Multimodal Features | Handles text, voice, and images in one system. |
Improved Audio Responses | Sounds more human and shows emotions. |
Faster Speed | Gives quicker answers while staying smart. |
Claude: Friendly and Ethical
Claude is great for chatting and is easy to use. It focuses on being ethical with a system called Constitutional AI (CAI). This makes sure its answers are fair and safe. If your app needs secure and kind interactions, Claude is a good pick.
People like it for summarizing, writing, and coding. For example, it can shorten long documents or help with programming. But it uses older training data, so it might not know the newest facts. Still, Claude is a solid choice for apps that value safety and fairness.
Tip: Claude’s ethical design is perfect for apps in healthcare or education.
Gemini: Smart and Detailed
Gemini is excellent at solving tough problems and understanding details. It scores higher than others in tests like GPQA Diamond and LMArena. For example, it got 84% on GPQA Diamond, beating GPT-4.5 by 5%. It’s great for science and math tasks that need deep thinking.
Gemini also understands context well, making it good for long chats or detailed analysis. Its scores in Humanity’s Last Exam and AIME 2025 show it can handle hard challenges. If your app needs strong reasoning, Gemini is a top choice.
Benchmark Test | Gemini 2.5 Pro Score | Comparison with Other Models |
|---|---|---|
Humanity’s Last Exam | 18.8% | Beats GPT-4.5, Claude 3.7 Sonnet, Grok 3 Beta, DeepSeek-R1 |
GPQA Diamond (Science) | 84% | 5% higher than GPT-4.5, much better than others |
Mathematics (AIME 2025) | 86.7% | Close to GPT-4.5 (86.5%), better than Claude 3.7 Sonnet and Grok 3 Beta, but lower than DeepSeek-R1 (93.3%) |
LMArena | 1443 | Leads the board, 40 points ahead of Grok-3 Preview (1404) |
QwQ: Small but Strong in Reasoning Tasks
If your app needs a small yet powerful model for reasoning, QwQ is a great pick. Its small size makes it fast and accurate. This is perfect for apps with limited power or needing quick answers.
QwQ does well in tests for reasoning skills. For example, in the AIME24 test, QwQ-32B scored 79.5, much higher than o1-mini's 63.6. In the BFCL test, QwQ-32B scored 66.4, beating DeepSeek-R1, which got 60.3. Even in LiveBench, which checks real-time reasoning, QwQ-32B stayed ahead with a score of 73.1.
Test Name | QwQ-32B | o1-mini | DeepSeek-R1 |
|---|---|---|---|
AIME24 | 79.5 | 63.6 | N/A |
BFCL | 66.4 | N/A | 60.3 |
LiveBench | 73.1 | N/A | 71.6 |
Tip: QwQ is a smart choice for apps that need to save money and work efficiently.
By using QwQ, your app can stay fast and reliable while handling reasoning tasks well.
DeepSeek: Best for Math and Coding
DeepSeek is the top model for apps needing advanced math and coding. It is very accurate in solving hard math problems step by step. The main version, DeepSeek R1, is highly reliable and performs better than most other models.
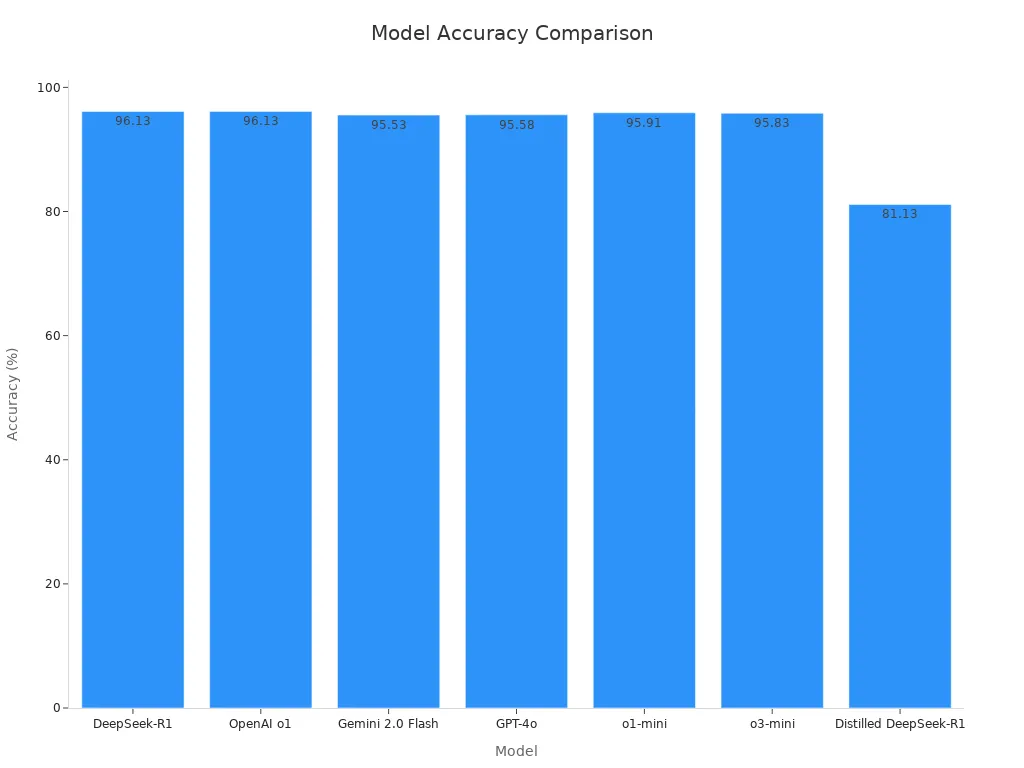
In tests, DeepSeek R1 scored 96.13% in math accuracy, matching OpenAI o1. It also beat Gemini 2.0 Flash (95.53%) and GPT-4o (95.58%). For coding tasks, DeepSeek R1 is also very dependable. However, the smaller version of DeepSeek R1 had lower accuracy, showing that smaller models may not perform as well.
Model | Accuracy (%) | Notes |
|---|---|---|
DeepSeek-R1 | 96.13 | Best for solving hard math problems step by step. |
OpenAI o1 | 96.13 | Same accuracy as DeepSeek-R1. |
Gemini 2.0 Flash | 95.53 | Good, but not as high as DeepSeek-R1. |
GPT-4o | 95.58 | Similar to Gemini 2.0 Flash. |
o1-mini | 95.91 | Slightly less accurate than full models. |
o3-mini | 95.83 | Good, but not as strong as DeepSeek-R1. |
Distilled DeepSeek-R1 | 81.13 | Much lower accuracy than the full version. |
DeepSeek R1 is the best choice for apps in education, banking, or any field needing exact math or coding. Adding DeepSeek to your app ensures top performance in these areas.
Benchmark Comparisons Across Tasks
Coding and Development Tasks
When picking models for coding, tests like HumanEval help. HumanEval checks how well models write Python code. AI Coding looks at correctness and if the code works. These tests show how good a model is at coding, helping you decide.
The OpenLLM Leaderboard tracks live test results on public data. It shows how models and humans differ in reasoning. Jaccard Similarity measures how close a model's code matches human logic. A score of 0.074 for code writing and 0.306 for test-making shows room to improve.
Metric/Method | What It Tests |
|---|---|
AI Coding | Checks coding skills, correctness, and if the code runs. |
OpenLLM Leaderboard | Tracks live test results on public datasets. |
Jaccard Similarity (Code Completion) | 0.074 - shows how far model logic is from human logic. |
Jaccard Similarity (Test-case Generation) | 0.306 - shows gaps in reasoning for making test cases. |
These tests help you pick a model that codes well for your app.
Reasoning and Problem-Solving
Reasoning tests check how models solve hard problems. For example, Figure 8 compares how models handle Formal Logic problems step by step. DeepSeek-R1 does better than others, showing strong reasoning skills. Figure 9 shows how models differ in solving Abstract Algebra problems.
Deep layers in models are key for reasoning. Freezing shallow layers lowers performance a bit. Freezing deeper layers causes big drops. This shows deep layers are needed for tough reasoning tasks. Models like DeepSeek-R1 also apply learned rules to new problems, making them reliable.
DeepSeek-R1 is best at Formal Logic tasks.
Abstract Algebra tests show accuracy differences between models.
Deep layers are crucial for solving math word problems.
Knowing these tests helps you find models great at reasoning and problem-solving.
Numerical and Analytical Capabilities
Numerical tests check how well models do math and analysis. DeepSeek-R1 scores 90.45% accuracy, beating most others. Gemini 2.0 Flash and GPT-4o do well but don’t match DeepSeek-R1 in tough tasks.
Publisher | Model Name | Accuracy (%) |
|---|---|---|
Gemini 2.0 Flash | 85.87 | |
OpenAI | GPT-4o | 64.88 |
o1-mini | 88.93 | |
o1 | 93.12 | |
o3-mini | 82.06 | |
DeepSeek | DeepSeek-1.5B | 65.64 |
DeepSeek-R1 | 90.45 |
For specific problems, DeepSeek-R1 leads in Abstract Algebra and College Math. It scores 94% and 96% accuracy, making it great for apps needing exact math answers.
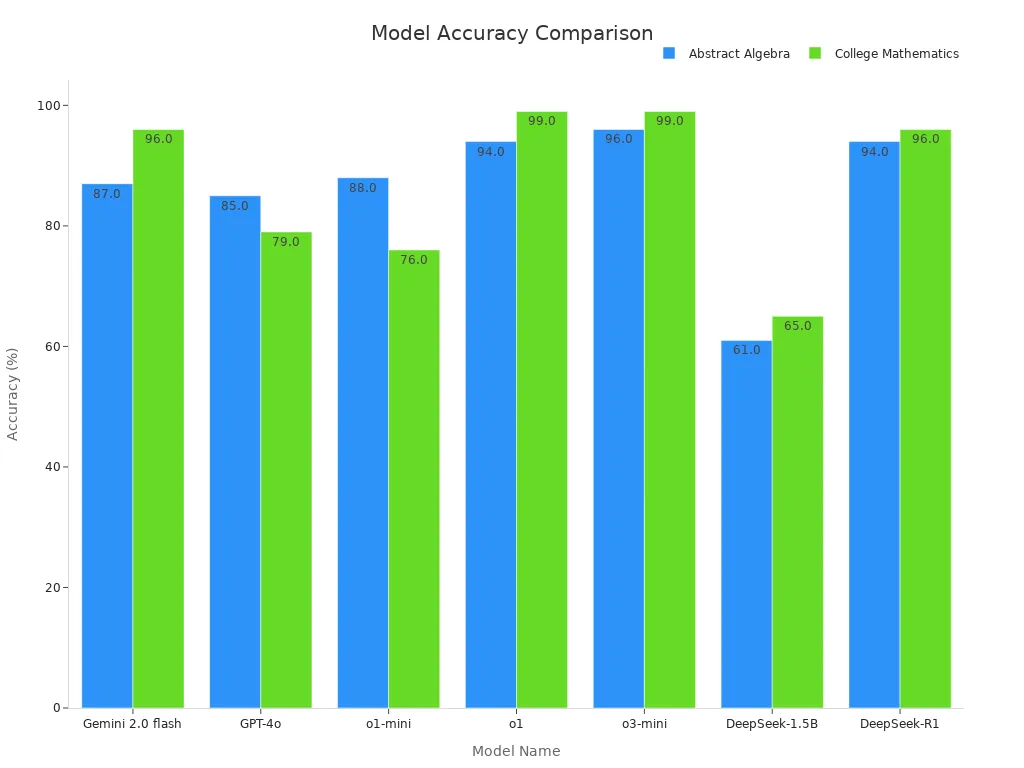
Using these tests ensures your app gets top math and analysis skills.
Creative and Conversational Outputs
Big language models are great at making creative and chatty content. They work well for apps needing stories, customer chats, or personal messages. These models help create fun content or smooth conversations.
For writing stories, tools like AI Dungeon use GPT-4 to let users make interactive tales. This is awesome for games or storytelling apps. In marketing, Copy.ai helps businesses by making social media posts and product details. It saves time while keeping things creative.
Chat features are just as amazing. Virtual helpers like Alexa and Google Assistant use these models to talk back and forth. They can answer questions, set alarms, or even tell jokes. For customer help, Bank of America’s Erica chatbot helps with tasks like checking accounts or paying bills. Zendesk also uses these models to give custom replies, making customers feel important.
Here’s a table showing some uses:
Use | Example |
|---|---|
Story writing | AI Dungeon uses GPT-4 to create interactive stories. |
Marketing content | Copy.ai makes social media posts and product descriptions. |
Customer service | Erica chatbot from Bank of America helps with banking tasks. |
Virtual helpers | Alexa and Google Assistant have two-way conversations using these models. |
Custom replies | Zendesk uses models to give personalized answers in customer support. |
When picking a model for creative or chat tasks, check if it makes natural and fun responses. A model that understands users and adjusts to them will improve your app’s experience.
Cost and Accessibility of Large Language Models

Pricing Models and Subscriptions
Knowing the cost of language models helps you pick the right one. Most models charge per token, meaning you pay for how much text is processed. This lets you adjust costs based on your app's needs. For example, a pricing tool can show costs by entering your token usage. This makes it simple to plan your spending.
Subscription plans differ too. Some have levels where higher ones include faster replies or better support. Others use pay-as-you-go plans, which work well if your app's usage changes a lot. By comparing these options, you can find a plan that fits your budget and app performance.
Open-Source vs Proprietary Options
Choosing between open-source and proprietary models depends on cost and tasks. Open-source models like DeepSeek-R1 are great for specific jobs like coding or reasoning. They cost less and handle longer tasks better, making them good for detailed work or long chats.
Proprietary models, like GPT-4, are more flexible and handle many tasks. They’re perfect for creative or general uses but usually cost more. If your app focuses on structured tasks, open-source might be better. For broader needs, proprietary models could offer more benefits.
Regional Availability and Support
Some language models aren’t available everywhere due to rules or licenses. Check if a model works in your area before choosing. Also, look at the support offered. Local support teams can solve problems faster, keeping your app running well.
For global apps, pick a model that works in many languages. Models like GPT-4 and Gemini are great for handling different languages, making them ideal for worldwide users. By checking availability and support, you can ensure your app stays accessible and reliable for everyone.
Integration Tips for Large Language Models
Using APIs for Easy Connection
APIs help link large language models to your app easily. They let you send questions and get answers without managing the model. For example, OpenAI and OpenRouter offer APIs to simplify this. These APIs can add features like creating text, summarizing, or handling both text and images.
To connect smoothly, follow some steps. Test the API with small tasks first to see how it works. Use tools like API-Bank to check how well the model works with other tools. This helps you find problems early. Also, keep checking the API's performance to make sure it fits your app.
Tip: Always double-check the model's answers since they might be wrong sometimes.
Making Your App Scalable
Scalability means your app works well even with more users. You can do this by using smart methods. Break code into smaller parts to manage token limits while keeping context. Mixing large models with static code analyzers improves accuracy for big tasks like analyzing long codes.
Some models, like Longformer or Reformer, are built for longer inputs. They use special techniques to handle big data better. Another way is prompt chaining. This method splits hard tasks into smaller ones, making it easier to handle large data.
Note: Plan for scalability if your app will have many users or handle lots of data.
Customizing with Fine-Tuning
Fine-tuning adjusts a language model to fit your app’s needs. Methods like LoRA and QLoRA change only a few settings, saving resources. For example, LoRA has improved models like Llama-2 in projects like SMART and FireAct. MITO is another method that combines fine-tuning with extra rules for better results.
Method | What It Does | Where It’s Used |
|---|---|---|
LoRA | Changes a few settings while keeping most unchanged. | Used in SMART, FireAct, and Agent Lumos for Llama-2 and LLaMA-3 models. |
QLoRA | Fine-tunes big models with fewer resources. | Applied in AgentOhana for xLAM-v0.1 models. |
MITO | Combines fine-tuning with extra rules for specific tasks. | Designed for Llama-2-7B. |
ENVISIONS | Refines models step-by-step through repeated tuning. | Uses updated data pairs for Llama-2. |
Reinforcement learning also helps customize models. It teaches models to improve by learning from feedback. This is great for apps that need to adapt to new tasks or situations.
Tip: Fine-tuning makes models work better and match your app’s goals closely.
Monitoring and Maintenance Best Practices
Keeping large language models (LLMs) running well takes regular care. If not watched, problems like errors or wrong answers can hurt your app. Follow these simple steps to keep your LLM working smoothly:
Check Performance Often: Watch how the model works over time. Look for changes where it starts making more mistakes. Fixing these early stops bigger issues later.
Use Tracking Tools: Tools with tracking features show helpful details. Logs, like input-output pairs, explain how the model answers users. Stats, like system health and usage, show how it handles different tasks.
Add Human Feedback: Let people give feedback to improve the model. Collecting and studying user feedback helps make the model’s answers better and fit your app’s needs.
These steps help keep your LLM strong and fix problems before they grow.
Using BYOM for Custom AI Tasks
Momen's Bring Your Own Model (BYOM) lets you add custom AI models to your app. This method allows you to use cloud-based models and adjust them for your needs. Platforms like Momen make it easy to set up in a few steps.
BYOM works with many models, like DeepSeek, Claude, Gemini, and QwQ. Each model is good at different tasks. For example, DeepSeek is great for math and coding, while Claude is best for safe and friendly chats. Mixing these models creates a system that fits your app perfectly.
To start, set up your cloud provider’s connection details. After that, you can adjust the model for specific tasks or link it to your workflows. This way, your app stays updated with the newest AI tools while keeping control of its features.
Tip: Check your BYOM setup often to make sure it still fits your app’s needs. This keeps your AI system working well and up-to-date.
Picking the right language model for your app in 2025 means knowing what each one does best. OpenAI GPT is great for creative tasks and flexibility. Claude focuses on being ethical and good at chatting. Gemini is strong at solving hard problems and understanding context. QwQ is small but works well for reasoning tasks. DeepSeek is the best for math and coding accuracy.
Think about what your app needs, like saving money, growing easily, or doing specific tasks. Tests like HellaSwag and ReasonEval show how good each model is. To choose wisely, rank models based on tests, reasoning skills, and real-world use. This helps you find the perfect AI model for your app’s needs.
FAQ
What is the best budget-friendly model for small apps?
To save money, QwQ is a smart pick. Its small size keeps costs low but still offers strong reasoning. It’s ideal for small apps needing good performance at a low price.
Can I use more than one model in my app?
Yes, you can! Tools like Momen allow you to add multiple models with the BYOM feature. For instance, use DeepSeek for coding and Claude for chatting to make your app more useful.
How can I customize a language model for my app?
Customizing a model makes it fit your app better. Use methods like LoRA or QLoRA to tweak settings. These methods save resources and improve tasks like customer help or writing content.
Which model works best for long chats?
Models with big context windows, like Gemini, are great for long chats. They remember past messages and give accurate replies, making them perfect for apps needing detailed talks or document reviews.
Are open-source models cheaper than proprietary ones?
Open-source models, like DeepSeek, cost less and work well for specific tasks like coding. Proprietary models, like GPT-4, are more flexible and handle many tasks. Pick based on your app’s needs and budget.
See Also
Exploring AI Models Benefits for Companies in 2025
12 Strategies for Integrating AI into SaaS Products in 2025
10 Creative AI Application Builders to Discover in 2025
